import os
os.getcwd() # 查看当前工作目录
os.setwd('文件路径') # 设置当前工作目录17 文件操作
本章介绍如何用Python操作本地文件,主要是读写操作。
17.1 文件路径操作
17.1.1 文件名称的正确写法
不论是读入本地的特定文件,还是将数据写入本地的某个文件,都需要明确要读/写的文件具体是哪一个,为此你需要向程序提供准确的文件名。 完整文件名由3部分组成:
- 路径,即文件所处的文件夹。
- 狭义的文件名,如你将一个Python脚本以
hello.py的名称存储在本地,其文件名就是hello。 - 扩展名,提示文件的格式,如
.py,.txt,.exe。
如,'C:/Users/HUAWEI/Desktop/工作簿1.xlsx'就是一个文件名。
文件路径中的分隔符有三种写法:
- 一个正斜杠
/ - 一个反斜杠,但文件名字符串前加 r(表示这个反斜杠不是转义字符的一部分)
- 两个反斜杠
\\(第 1 个反斜杠转义第 2 个反斜杠)
注记不能使用一个反斜杠\backslash作文件路径的分隔符的理由
一个反斜杠代表转义字符,具有特殊含义。如\n会被解读为换行符,而不是表示文件夹的层级关系。
在Windows平台上,右击文件图标,选择属性,可看到文件路径。
注意这里显示的路径是1个反斜杠,不能直接使用,需替换为\\或/。
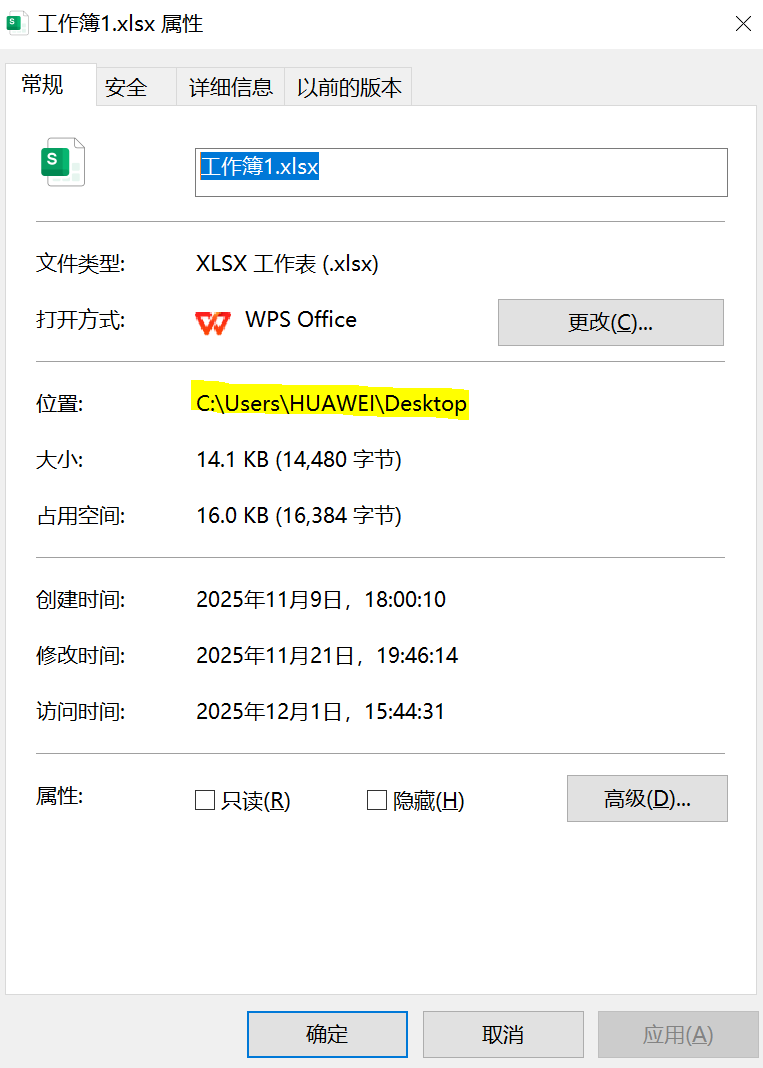
右击-属性查看文件路径。此路径用1个反斜杠作分隔符。17.1.2 当前工作目录
读数据时提供的文件名如果不包含路径,程序会在当前工作目录(current working directory)中寻找同名文件。 os模块可以查看和设置当前工作目录。
使用Jupyter Notebook时,当前工作目录是.ipynb文件所在的文件夹的当前工作目录。
在本地项目中,工作目录是创建项目时就设定的项目文件夹。 如果项目涉及数量众多、类型各异的文件, 建议在项目文件夹中建立data,figure,code等文件夹,分门别类地存放数据、图片和代码等文件,读写文件的路径可以统一为形如'./data/'的相对路径 (在文件路径中,.代表当前文件夹)。
形如'C:/Users/HUAWEI/Desktop/工作簿1.xlsx'的完整路径称为绝对路径,形如'./data/工作簿1.xlsx'、用.表示当前文件夹的路径称为相对路径。
import pandas as pd
# 通过绝对路径读取文件
path = '文件路径'
df = pd.read_csv(path + '/file.csv')
# 通过相对路径读取文件
# 项目文件夹的data子文件下放数据文件
df = pd.read_csv('./data/file.csv')17.2 读写表格数据
表格数据(tabular data)的一行代表一个观测,一列代表一个变量,是数据科学和数据分析中最常见的数据格式。
表格数据有3种常见格式:.csv, .xlsx, .txt。 csv全称comma separated values,即逗号分隔值,每行用逗号分隔各变量;.xlsx是微软Excel处理的文件格式;.txt是纯文本文件。
pandas 是 Python 专注于数据分析的第三方库,对这3种格式的数据都能读写。
import pandas as pd
# 将表格数据读入程序
df = pd.read_csv('./data/file.csv')
df = pd.read_excel('./data/file.xlsx') # 默认读取第1个工作簿
df = pd.read_table('./data/file.txt')
# 将文件保存为表格数据
df.to_csv('./data/file.csv')
df.to_excel('./data/file.xlsx')
df.to_csv('./data/file.txt', sep = '\t') # 各列以制表符分隔pandas 没有 to_table()方法,但 to_csv()可以将输出文件的扩展名写为 txt,用 sep参数规定分隔符。
pd.read_csv() 默认使用 utf-8 解码。如果文件以其他方式编码,可能报错 UnicodeDecodeError。对中文文件,可尝试参数encoding = 'gbk'。
上面的代码中,读入的数据对象df的类型是pandas库定义的类型数据框data.frame。 在用Python做数据分析的课程中,会对pandas的使用做详细讲解。
17.3 读写一般文件
17.3.1 文本文件,二进制文件
文本文件用来保存肉眼可见的字符,扩展名是.txt,.py等。
二进制文件用来保存视频、图片、音乐等不可用字符表示的内容。
二进制文件和文本文件都是以二进制数字 0,1 保存在磁盘上的数据。 文本文件用 ASCII、UTF-8、GBK 等字符编码,文本编辑器(如记事本,vscode 等)通过识别出这些编码格式,将编码值转换成字符显示; 二进制数据没有字符编码含义,文本编辑器按照字符编码格式解析,就得到乱码。
17.3.2 缓冲区
存储器的速度越快,能耗越高,材料成本越贵,因此速度快的存储器的容量都比较小。
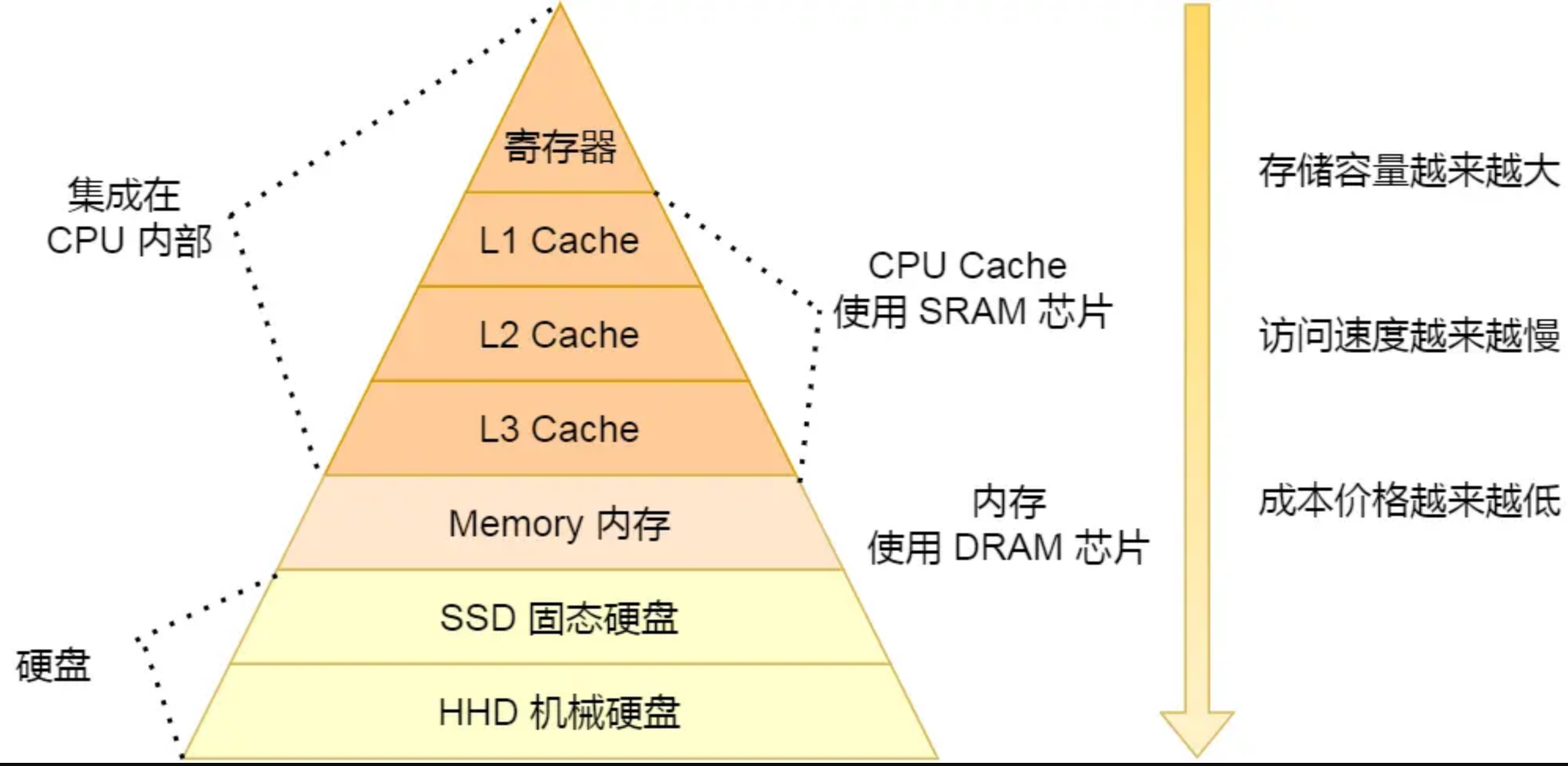
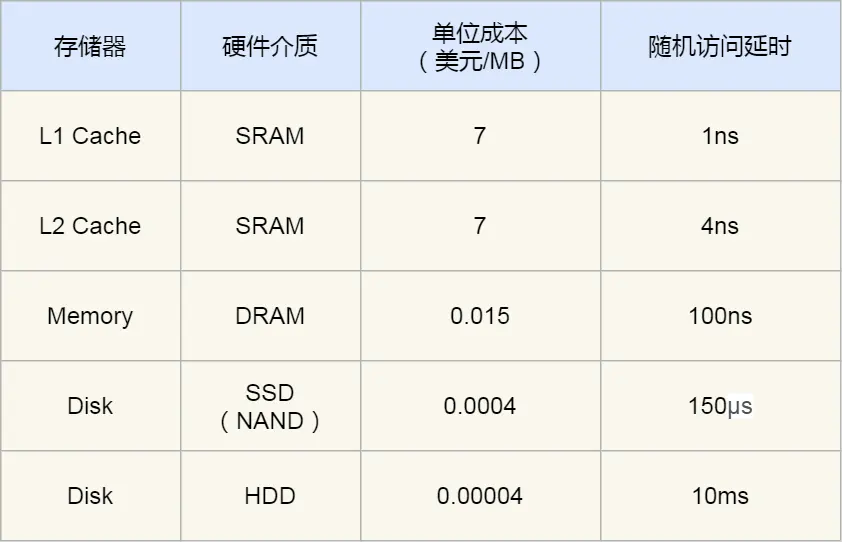
计算机在内存中预留一定的存储空间,称为缓冲区(buffer),用来暂存输入或输出数据。 设置缓冲区可以减少输入输出设备的读写次数,提高效率。如:
- 硬盘的速度远低于 CPU,当向硬盘写入数据时,程序需要等待,不能做任何事情,就好像卡顿了一样,用户体验非常差。
- 计算机上绝大多数应用程序都需要和硬件打交道,如读写硬盘、向显示器输出、从键盘输入等,如果每个程序都等待硬件,整台计算机也会变得卡顿。
- 如果将数据先放入缓冲区(内存的读写速度也远高于硬盘),程序可以继续往下执行,等积累了一定量的数据,再将缓冲区的所有数据一次性写入硬盘,这样程序就减少了等待的次数,变得流畅起来。
Python在内存区为每一个正在被使用的文件开辟一个文件缓冲区。 从内存向磁盘输出数据必须先送到内存中的缓冲区,装满缓冲区后才一起送到磁盘去。 从磁盘向计算机读入数据,则一次从磁盘文件将一批数据输入到内存缓冲区至充满,然后再从缓冲区逐个地将数据送到程序数据区。
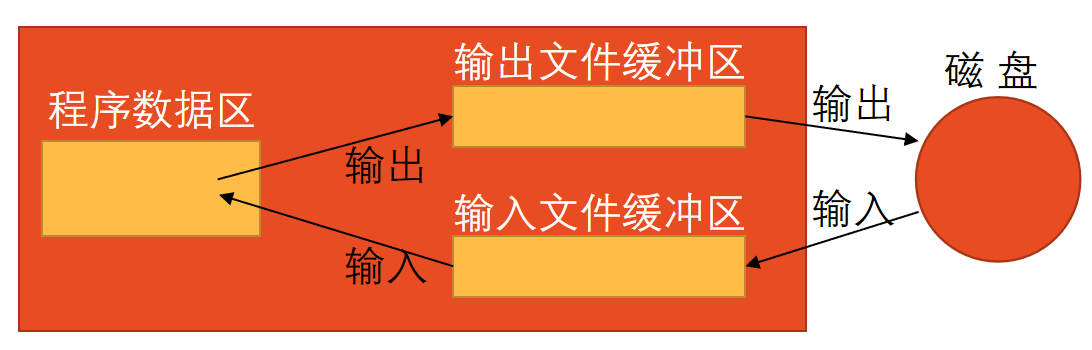
17.3.3 文件的打开,关闭
打开文件,就是建立程序与文件的连接,为文件建立信息区和缓冲区。 文件信息区是内存中的一个区域,用来存放操作相关文件所需的信息,如文件名称,文件状态,文件当前位置等。 程序通过操作文件信息区,实现对本地文件的操作。
关闭文件,指撤销文件信息区和文件缓冲区,,关闭后用户就无法再操作文件。
为了安全、可靠地进行文件操作,操作文件前要打开文件,操作结束后要关闭文件。
你应该能够看出,程序对文件的打开和关闭,与操作系统地图形界面中双击文件图标打开、点击小红叉关闭,并不是相同的概念。
17.3.4 打开关闭文件的Python函数
Python中,open()打开文件,close()关闭文件。
# 打开文件
f = open(file, mode='r', encoding=None,...)
# 关闭文件
f.close()filename:要打开的文件名称,通常是字符串,包括文件路径、文件名称、扩展名mode:文件访问方式,见 表 17.1encoding:文本文件的编码方式,默认编码与平台有关open()返回一个文件对象f,文件对象f本质上就是相关文件的信息区- 为了安全和资源管理,文件不用后应用
close()关闭
| 模式 | 描述 | 文件存在 | 文件不存在 |
|---|---|---|---|
| “r” | 只读 | 打开成功 | 打开失败 |
| “w” | 只写 | 清空文件 | 创建新文件 |
| “a” | 追加 | 追加写入 | 创建新文件 |
| “x” | 仅创建 | 打开失败 | 创建新文件 |
表 17.1 中的字符串还可以与't', 'b','+'组合。 't'用于文本文件,'b'用于二进制文件。 '+'使得访问方式兼具读写。如mode = 'rt+',就是以读写方式打开文本文件,且不清空文件。 只有含有'w'的访问方式才会清空现有文件。 默认访问方式是'rt'(以只读方式打开文本文件)。
17.3.5 读写文件的Python函数
open()返回的文件对象一个序列,具有 read(),write() 等方法。
| 方法 | 含义 |
|---|---|
read(size) |
返回文本文件的 size 个字符 返回二进制文件的size个字节 省略 size 则读入所有数据。 |
readline() |
返回一行(字符串),重复应用返回下一行。 |
readlines(hint) |
返回 hint 行(列表),省 hint 则读入所有行。 |
write(string) |
将字符串 string 写入文件,返回写入的字符数。 |
writelines(lines) |
lines 是一个列表,列表元素是字符串,每个字符串的最后一个字符应当是行之间的分隔符,如换行符 |
flush() |
刷新写入缓冲区 |
文件打开后必须关闭,一般有两种方法实现:
- 用
try...except...finally确保文件打开后被关闭。
try代码块被执行,如果出现报错,执行except代码块的内容;无论是否执行except代码块,最终都会执行finally代码块。
f = None
try:
f = open("file")
except:
# 报错时执行的操作
finally:
if f is not None:
f.close()- 用with语句定义一个上下文,确保打开的文件自动关闭。
此时不需使用close(),with代码块结束后文件将自动关闭。
with open(filename, 'r', encoding = 'utf-8') as f:
# 对文件进行的处理操作# 用with
import sys
filename = sys.argv[0]
line_no = 0
with open(filename, 'r', encoding = 'utf-8') as f:
for line in f:
line_no += 1
print(line_no, ":", line)
# 不用with
import sys
filename = sys.argv[0]
f = open(filename, 'r', encoding = 'utf-8')
line_no = 0
while True:
line_no += 1
line = f.readline()
if line:
print(line_no, ":", line)
else:
break
f.close()17.4 序列化
序列化(serialize)指将对象转换为字节序列; 反序列化是将字节序列还原为对象。
为什么要序列化?虽然对象在内存中也是用字节存储的,但内存中的字节数据不是自描述的,其具体含义依赖于编程语言、编译器、甚至操作系统。换句话说,把 A 机器内存的一段字节直接复制到 B 机器,B 机器无法理解。
可用 pickle, cpickle,json 等模块实现序列化与反序列化:
- cpickle 用 C 实现,比 pickle 更快。可序列化几乎一切Python 对象,但安全性差。
- JSON(JavaScript Object Notation,Java 对象标记)是网络数据交换的流行格式。json 模块可以将部分 Python 对象序列化为 json 文件,将 json 文件反序列化为 Python 对象。
# pickle API
import pickle
pickle.dump(obj, file, protocol=None ,...)
pickle.dumps(obj, protocol=None ,...)
pickle.load(file...)
pickle.loads(data...)| API | 含义 |
|---|---|
pickle.dump(obj, file) |
将对象 obj 序列化后的字节数据写入文件对象 file |
pickle.dumps(obj) |
返回对象 obj 序列化后的 bytes 对象 |
pickle.load(file) |
反序列化,参数是存储序列化字节数据的文件对象 file |
pickle.loads(data) |
反序列化,参数是 bytes 对象 |
pickle 函数中有个参数 protocol,表示序列化使用的协议:
- pickle 协议是 Python 定义的序列化规则,不同版本的协议优化了数据格式、性能或支持新特性。
- Python 随着版本更新引入新的协议,但保持向后兼容:支持高版本协议的 Python 可以反序列化低版本协议序列化的数据;不支持高版本协议的 Python 不能反序列化高版本协议序列化的数据。
- 序列化一般不需显式提供 protocol,程序会选择当前 Python版本默认的协议。
| 协议版本 | Python 引入版本 | 特点 |
|---|---|---|
| 0 | Python 1.4 | 人类可读的 ASCII 格式(兼容性最强,但速度慢、体积大) |
| 1 | Python 1.4 | 较旧的二进制格式(略高效于协议 0) |
| 2 | Python 2.3 | 支持 Python 2 的类的新特性(如 __slots__) |
| 3 | Python 3.0 | 专为 Python 3 设计,不兼容 Python 2(Python 3.0-3.7的默认协议) |
| 4 | Python 3.4 | 支持更大对象、优化存储效率(Python 3.8+的默认协议) |
| 5 | Python 3.8 | 支持外存数据(out-of-band data)和性能优化 |
# 序列化
import pickle
with open("dataObj1.dat", "wb") as f:
s1 = "Hello!"
c1 = 1 + 2j
t1 = (1,2,3)
d1 = dict(name = "Mary", age = 19)
pickle.dump(s1, f)
pickle.dump(c1, f)
pickle.dump(t1, f)
pickle.dump(d1, f)# 反序列化
import pickle
with open("dataObj1.dat", "rb") as f:
o1 = pickle.load(f)
o2 = pickle.load(f)
o3 = pickle.load(f)
o4 = pickle.load(f)
print(type(o1), str(o1))
print(type(o2), str(o2))
print(type(o3), str(o3))
print(type(o4), str(o4))json 模块能序列化部分 Python 对象为 JSON 字符串,便于传播。但 json 并不支持所有 Python 对象,如它不能直接处理集合,需要转换为列表。
| API | 含义 |
|---|---|
json.dump(obj, file) |
将 obj 对象序列化为 JSON 字符串,写入文件 file |
json.load(file) |
从文件 file 读取 JSON 字符串,返回反序列化后的该对象 |
json.dumps(obj) |
将 obj 对象序列化为 JSON 字符串,返回JSON 字符串 |
json.loads(s) |
将 JSON 字符串 s 反序列化后返回 |
| Python对象类型 | JSON类型 |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float, int- & float-derived Enums | number |
| True | true |
| False | false |
| None | null |
import json
data = [{'a': 'A', 'b': (2,4), 'c':3.0}]
str_json = json.dumps(data)
str_json
data1 = json.loads(str_json)
data1'[{"a": "A", "b": [2, 4], "c": 3.0}]'[{'a': 'A', 'b': [2, 4], 'c': 3.0}]import json
urls={'baidu':'http://www.baidu.com/',
'sina':'http://www.sina.com.cn/',
'tencent':'http://www.qq.com/',
'taobao':'https://www.taobao.com/'}
with open(r'c:\pythonpa\data.json', 'w') as f:
json.dump(urls, f)
with open(r'c:\pythonpa\data.json', 'r') as f:
urls = json.load(f)
print(urls)17.5 练习
- 文件类型判断。
传媒从业者经常需要转换文件格式。 如知名视觉小说游戏开发引擎Ren’Py仅支持webm格式的视频文件。 因此视觉小说开发者经常要将mp4文件转webm。 许多视频插入问题失败的问题,也来源于开发者误将mp4文件认为是webm文件使用。
因此判断文件类型是工作刚需。许多用户通过文件扩展名来判断文件类型。 但文件扩展名可以手动更改,而仅仅更改扩展名是不能改变文件格式的,反而给文件类型识别增加难度。 正确转换文件格式需要借助专门工具,如 https://www.freeconvert.com/mp4-to-webm 。
判断文件类型的更可靠的方式是文件签名(file signature)。 文件签名指文件的前几个字节码,特定类型的文件通常有着给定的文件签名。 你可以查阅文件签名不完全表格。如:
- MP4文件从第4个字节开始(索引从0开始)的四个字节固定为
66 74 79 70,后面接续的字节码可能是4D 53 4E 56,69 73 6F 6D,6D 70 34 32。 - webm文件必定以
1A 45 DF A3开头(虽然mkv文件也具有相同开头)
一些软件(如Windows平台的HxD)可以让你方便地查看文件的字节码。
编写代码,判断一个视频文件是mp4格式,还是webm格式。


注记参考答案
def check_video_format(filename):
'''检测文件是webm还是mp4,只识别特定4种MP4,其他格式返回unknown'''
try:
with open(filename, 'rb') as f:
header = f.read(12)# 读取前12个字节的文件头
except Exception as e:
return f'error: {str(e)}'
if header[:4] == b'\x1A\x45\xDF\xA3':
return 'webm'
elif header[4:8] == b'ftyp':
if header[8:] in [b'\x4D\x53\x4E\x56', b'\x69\x73\x6F\x6D', b'\x6D\x70\x34\x32']:
return 'mp4'
else:
return 'other mp4'
else:
return 'unknown'