s1 = '春花秋月何时了'
s2 = "此去泉台招旧部,旌旗十万斩阎罗"
s3 = '''
青青子衿
悠悠我心
但为君故
沉吟至今
'''
def foo():
'''我是一个很简单的函数
不接受任何参数
也没有任何副作用
'''
pass8 字符串str
8.1 string字符串字面量
str是Python用来实现字符串(string)的数据类型。
字符(character):自然语言中的单个符号,如英文的a,中文的爱,都是字符。
字符串(string):一个或多个字符构成的序列。
Python的字符串字面量,需要用引号包围。 引号可以是单引号',双引号",或三个单引号形成的三引号'''。 双引号与单引号没有区别,三引号包围的字符串可以换行。因此三引号字符串常用于写函数说明——为了讲清楚函数的功能与用法,往往要写大几段。
相邻或仅被空格分隔的字符串,会被识别为一个字符串。
'a' 'b''ab'
注记 8.1: 试一试:在双引号/单引号包围的字符串中换行会如何?
'道可道
非常道'Cell In[3], line 1 '道可道 ^ SyntaxError: unterminated string literal (detected at line 1)
8.2 转义字符
以反斜杠\开头的字符序列,称为转义序列(escape sequence)。
转义序列用来表示不能或不便用一般字符表示的字符。
字符串前添加r,表示该字符串中的\不转义,视为普通反斜杠。r代表raw(原始)。
| 转义字符 | 含义 | ASCII码 |
|---|---|---|
\n |
换行符 | 10 |
\t |
水平制表符,移动到下一个制表位 | 9 |
\b |
退格(backspace),删除前一个字符 | 8 |
\r |
回车,回到本行开头,用于覆盖当前行 与现代键盘的Enter不同 |
13 |
\\ |
一个反斜杠 | 92 |
\' |
一个单撇号 | 39 |
\" |
一个双撇号 | 34 |
\ooo |
1~3位八进制数代表的字符,如\0,\111 |
|
\xhh |
2位16进制数代表的字符,如\x00,\x1E |
换行符效果
print("春花秋月何时了\n往事知多少")春花秋月何时了
往事知多少制表符效果:每个公式结束后打印制表符,保证各列公式对齐
for i in range(1, 10):
for j in range(1,10):
print(i, "*", j, "=", i*j, sep = "", end="\t")
print("\n")1*1=1 1*2=2 1*3=3 1*4=4 1*5=5 1*6=6 1*7=7 1*8=8 1*9=9
2*1=2 2*2=4 2*3=6 2*4=8 2*5=10 2*6=12 2*7=14 2*8=16 2*9=18
3*1=3 3*2=6 3*3=9 3*4=12 3*5=15 3*6=18 3*7=21 3*8=24 3*9=27
4*1=4 4*2=8 4*3=12 4*4=16 4*5=20 4*6=24 4*7=28 4*8=32 4*9=36
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25 5*6=30 5*7=35 5*8=40 5*9=45
6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36 6*7=42 6*8=48 6*9=54
7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49 7*8=56 7*9=63
8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64 8*9=72
9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
将制表符替换为固定宽度空格的效果
for i in range(1, 10):
for j in range(1,10):
print(i, "*", j, "=", i*j, sep = "", end=" ")
print("\n")1*1=1 1*2=2 1*3=3 1*4=4 1*5=5 1*6=6 1*7=7 1*8=8 1*9=9
2*1=2 2*2=4 2*3=6 2*4=8 2*5=10 2*6=12 2*7=14 2*8=16 2*9=18
3*1=3 3*2=6 3*3=9 3*4=12 3*5=15 3*6=18 3*7=21 3*8=24 3*9=27
4*1=4 4*2=8 4*3=12 4*4=16 4*5=20 4*6=24 4*7=28 4*8=32 4*9=36
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25 5*6=30 5*7=35 5*8=40 5*9=45
6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36 6*7=42 6*8=48 6*9=54
7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49 7*8=56 7*9=63
8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64 8*9=72
9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
反斜杠后转义8进制数或16进制数,得到的是相应ASCII码点。因此\x61看似有4个字符,其实只表示了1个字符
# 16进制数61的十进制表示是97,97是字符"a"的ASCII码
print("\x61")a
注记小测
你是否能解释下列输出?1
print(len("\x61\12\nabd"))6r字符串效果
print(r'以r开头的字符串中,\n反斜杠不再转义')以r开头的字符串中,\n反斜杠不再转义8.3 字符串方法
Python可用于字符串的方法非常多,详见文本与二进制字符串方法总结。
这些方法据其功能可分为7类:
- 格式化,如
format() - 查找替换,如
find(), index(), count(), startswith(), endswith() - 拆分连接,如
split(),join() - 字符串分类,如
isalpha(), isnumeric(), isalnum(), isdigit() - 大小写转换,如
lower(), upper() - 空格添加/删除,如
strip() - 翻译与编码,如
encode(), decode()
字符串方法的应用方式,是字符串对象.方法名称([方法参数])。
| 方法 | 效果 |
|---|---|
s.split(sep=None) |
根据特定字符将字符串拆分,返回列表 |
s.join(iterable) |
将可迭代对象iterable连接为字符串,用s作为连接符 |
split()效果
s = 'The Mole had been working very hard all the morning, spring-cleaning his little home.'
s.split()['The',
'Mole',
'had',
'been',
'working',
'very',
'hard',
'all',
'the',
'morning,',
'spring-cleaning',
'his',
'little',
'home.']s = 'a!b!c!d'
s.split("!")['a', 'b', 'c', 'd']
注记split的用法细节
- 如果出现连续n个分隔符,会在相应位置返回n-1个空字符
- 如果在给定分隔符的情况下分割空字符,会返回空字符
"1*2**3***4****".split("*")['1', '2', '', '3', '', '', '4', '', '', '', '']"".split("*")['']join()效果:
s = 'The Mole had been working very hard all the morning, spring-cleaning his little home.'
word_list = s.split()
"*".join(word_list)'The*Mole*had*been*working*very*hard*all*the*morning,*spring-cleaning*his*little*home.'8.4 字符串格式化
字符串格式化的目的是将字符串以特定格式输出,如:
- 输出数值时,保留给定的小数位数,以特定进制输出
- 字符串占据的最小宽度、是左对齐还是右对齐
Python有4种方法实现字符串的格式化:
- printf式的格式化
- 字符串的str.format()方法
- 以F或f为前缀的f-字符串f-string
- 使用$的模板格式化string.Template
# 使用$的模板格式化
from string import Template
s = Template('$who likes $what')
print(s.substitute(who='tim', what='kung pao'))
d = dict(who='tim')
#报错 Template('Give $who $100').substitute(d)
#报错 Template('$who likes $what').substitute(d)
print(Template('$who likes $what').safe_substitute(d))tim likes kung pao
tim likes $what8.4.1 printf()式格式化
C语言的printf()函数可以输出数据,但需要格式字符说明打印的数据的类型。 因为相同的数据如果被解释为不同类型,其代表的含义不尽相同。 为了保持语言的简洁性,printf()函数将确定数据类型的任务交给程序员。
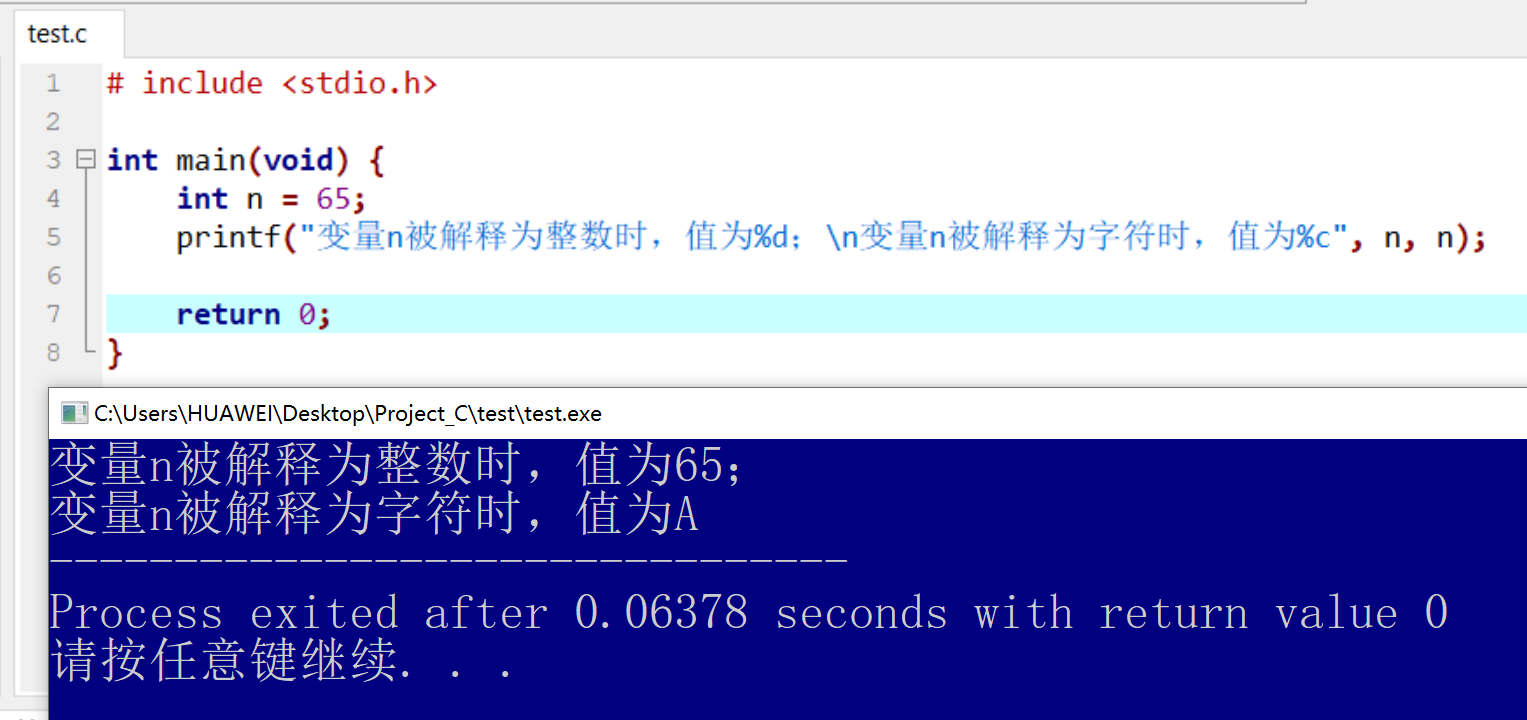
Python中使用%的格式化与C语言中printf()的格式化输出类似。
# %格式化的典型应用
# 与C语言的格式化输出类似,但代码更冗长
# %s表示此处要插入一个字符串
# %d表示此处要插入一个整数
# 字符串后面有一个%,其后跟要插入的具体对象。如果对象有多个,需要以元组形式提供
print('%s has %d quote types.' % ('Python', 2))Python has 2 quote types.# 关键字方式传递
print('%(language)s has %(number)03d quote types.' %
{'language': "Python", "number": 2})Python has 002 quote types.完整的%格式化字符串可能依次含有下列组成部分:
%符号,标志转换说明符的开头- 可选的
(字典键),用于以字典形式提供数据 - 可选的转换标志,包括
#,0,-,(空格),+2 - 可选的最小宽度,可选的
.精度。最小宽度和精度可以以*的形式提供,此时需将它们作为参数,在待输出的数据之前提供。 - 可选的长度修饰符。C语言具有长度修饰符
h(short),l/L(long),但这一选项在Python中无意义,会被忽略。 - 转换类型字符,见 表 8.1 和 表 8.2。
| 转换类型 | 对象类型 | 输出形式 |
|---|---|---|
| s | 字符串 | 字符串(string) |
| d | 整数 | 10进制整数(decimal) |
| o,x,X | 整数 | o: 8进制(oct) x,X: 16进制(hex) 不含前缀0b/0o/0x/0X |
| f,F | 浮点数 | 10进制浮点数(float) 精度p(小数点后的位数)默认为6 F将无限、非数值输出为INF、NAN,f输出小写版本 |
| e,E | 浮点数 | 10进制科学计数法 小数点前仅一位数 精度(小数点后的位数)默认为6 |
| g,G | 浮点数 | 选用%f,%F或%e,%E,一般是更紧凑的形式输出 |
| 转换类型 | 对象类型 | 输出形式 |
|---|---|---|
| i | 整数 | 十进制整数(相当于d) |
| c | 整数 字符 |
字符 |
| r a |
字符串 | 用repr()输出用 ascii()输出 |
| % | - | 相当于转义符号,输出% |
8.4.2 str.format()格式化
%格式化能支持整数、浮点数、字符串等比较基础的数据类型,但对元组等Python的内置数据类型的支持不太好,如
# 可以正常输出单个字符串
msg = 'disk failure'
'error: %s' % msg'error: disk failure'# 不支持直接输出长度>1的元组对象
msg = ('disk failure', 32)
'error: %s' % msg--------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[19], line 3 1 # 不支持直接输出长度>1的元组对象 2 msg = ('disk failure', 32) ----> 3 'error: %s' % msg TypeError: not all arguments converted during string formatting
# 需要将输出的元组对象包装为长度=1的元组
msg = ('disk failure', 32)
'error: %s' % (msg,) "error: ('disk failure', 32)"为改进这些缺点,字符串的format()方法应运而生。
一般用"格式化字符串".format(参数)的形式使用format方法,也能用str.format("格式化字符串", 参数)的形式。
格式化字符串包含原样输出的字符,以及说明格式的替换字段。 替换字段位于花括号{}中,由字段名称、转换方式和格式说明符3部分组成:
- 字段名称(field name),提示插入的数据内容,可以是索引或关键字,分别对应位置参数与关键字参数。字段名称后可以带索引(形式为
字段名称[索引编号]),带对象属性(形式为字段名称.对象属性),但不能带字典的键。
# str.format()方法格式化
# {}中写要填入的format()中的参数的索引
"{1} expects the {0} Inquisition!".format("Spanish", "Nobody")
"The sum of 1 + 2 is {0}".format(1+2)
'{0}, {1}, {2}'.format('a', 'b', 'c')
'{2}, {1}, {0}'.format('a', 'b', 'c')
'{0}{1}{0}'.format('abra', 'cad')'Nobody expects the Spanish Inquisition!''The sum of 1 + 2 is 3''a, b, c''c, b, a''abracadabra'# 用*解包序列对象
print('{2}, {1}, {0}'.format(*'abc'))
print('{2}, {1}, {0}'.format(*['a','b','c']))c, b, a
c, b, a# 如果是顺序传入,索引可以省略
"The sum of 1 + 2 is {}".format(1+2)
'{}, {}, {}'.format('a', 'b', 'c')'The sum of 1 + 2 is 3''a, b, c'# format()也接受关键字参数,{}中填写关键字
"The sum of {a} + {b} is {answer}".format(answer=1+2, a=1, b=2)
'Coordinates: {latitude}, {longitude}'.format(latitude='37.24N', longitude='-115.81W')
# **将字典解包为关键字参数
coord = {'latitude': '37.24N', 'longitude': '-115.81W'}
'Coordinates: {latitude}, {longitude}'.format(**coord)'The sum of 1 + 2 is 3''Coordinates: 37.24N, -115.81W''Coordinates: 37.24N, -115.81W'# 字段名称后跟对象属性
#
c = 3 - 5j
('The complex number {0} is formed from the real part {0.real} '
'and the imaginary part {0.imag}.').format(c)'The complex number (3-5j) is formed from the real part 3.0 and the imaginary part -5.0.'# 字段名称后跟索引
coord = (3, 5)
'X: {0[0]}; Y: {0[1]}'.format(coord)'X: 3; Y: 5'- 转换方式(conversion),可选,以
!开头,可取值s(默认),r,a,分别用str(),repr(),ascii()处理输出内容。
repr(),返回对象的官方字符串表示(representation)。 将repr()的结果传入eval(),应该能得到与原始对象相等的对象。 对于字符串对象,repr()保留引号,将转义字符中的\转义。ascii()与repr()类似,但会将非ASCII字符用\x或\u或\U转义。
# repr()与ascii()的效果
repr('道可道\n非常道')
eval("'道可道\\n非常道'")
ascii('道可道\n非常道')
eval("'\\u9053\\u53ef\\u9053\\n\\u975e\\u5e38\\u9053'")"'道可道\\n非常道'"'道可道\n非常道'"'\\u9053\\u53ef\\u9053\\n\\u975e\\u5e38\\u9053'"'道可道\n非常道'# 对比转换方式r与s
"repr() shows quotes: {!r}; str() doesn't: {!s}".format('test1', 'test2')"repr() shows quotes: 'test1'; str() doesn't: test2"- 格式说明符(format spec),以
:开头,说明数据输出的具体格式,由3个可选部分依次组成:
- 选项(option),规定对齐方式等格式。
- 字段宽度.精度(width, precision)。
- 字段宽度指输出的最小宽度
- 精度,对于浮点数f,指的小数点后的位数;对于浮点数g,指的是所有有效数字位数;对于字符串,是字符串的最大宽度
- 数据类型(type),见 表 8.1 和 表 8.4。
str.format()方法的选项
| 选项类型 | 选项符号 | 含义 |
|---|---|---|
| 对齐 | < |
左对齐 |
> |
右对齐 | |
^ |
居中 | |
= |
用于整数、浮点数对象 使填充字符位于符号后、数字前,用于 +000000120形式的输出这是字段宽度前有0时的默认对齐方式 |
|
| 符号 | - |
默认选项,仅负数显示符号 |
+ |
正负数都显示符号 | |
| 空格 | 正数前加一个空格 | |
| 分隔 | , |
对于数值对象每三位插入, |
_ |
对于数值对象每三位插入_对于 b,o,x,X等类型数据,每4位插入该符号 |
|
| 其他 | # |
用于数值数据类型,显示另类形式(alternate form)如: 2/8/16进制显示前缀 浮点数总是显示小数点 |
对齐选项前面可以提供填充字符,默认以空格填充。
# format()对齐选项示例
# 对齐选项钱可以加填充符号
'{:<30}'.format('左对齐,最小输出宽度为30')
'{:>30}'.format('右对齐,最小输出宽度为30')
'{:^30}'.format('居中,最小输出宽度为30')
'{:*^30}'.format('居中,以*填充两端')'左对齐,最小输出宽度为30 '' 右对齐,最小输出宽度为30'' 居中,最小输出宽度为30 ''**********居中,以*填充两端***********'# format()符号选项示例
'{:-f}; {:-f}'.format(3.14, -3.14) # 默认只显示负号
'{:+f}; {:+f}'.format(3.14, -3.14) # 正负号都显示
'{: f}; {: f}'.format(3.14, -3.14) # 正数前添加空格'3.140000; -3.140000''+3.140000; -3.140000'' 3.140000; -3.140000'# format()的#选项示例
"10进制: {0:d}; 16进制 {0:x}; 8进制: {0:o}; 2进制: {0:b}".format(42)
"10进制: {0:d}; 16进制 {0:#x}; 8进制: {0:#o}; 2进制: {0:#b}".format(42)'10进制: 42; 16进制 2a; 8进制: 52; 2进制: 101010''10进制: 42; 16进制 0x2a; 8进制: 0o52; 2进制: 0b101010'# format()分隔符选项示例
'{:,}'.format(1234567890)
'{:_}'.format(1234567890)
'{:_b}'.format(1234567890)
'{:_x}'.format(1234567890)
'{:_}'.format(123456789.123456789)'1,234,567,890''1_234_567_890''100_1001_1001_0110_0000_0010_1101_0010''4996_02d2''123_456_789.12345679'str.format()方法与f-string的专属类型说明符
| 类型字符 | 对象类型 | 输出形式 |
|---|---|---|
| 无 | 字符串 整数 浮点数 |
同s(字符串) 同d(整数) 同g或G |
| c | 整数 | 字符:整数为unicode码点时对应的字符 |
| n | 整数 浮点数 |
同d或g,在整数部分添加适合当前语言的分隔符 |
| % | 浮点数 | 百分数 |
# 类型说明符示例
points = 19
total = 22
'Correct answers: {:.2%}'.format(points/total)'Correct answers: 86.36%'str.format()方法字符串允许替换字段嵌套一层。
# 替换字段嵌套
import decimal
"result: {value:{width}.{precision}f}" .format(width = 10, precision = 4, value = decimal.Decimal("12.34567"))'result: 12.3457''在format方法中显示花括号{{}},需要用双花括号{}'.format('{{}}')'在format方法中显示花括号{},需要用双花括号{{}}'
注记
format()方法无法以花括号{作为填充字符。
为了美观,人们也不会想用{这种不对称的符号来作填充字符。
注记内置函数format()
Python还有一个内置函数format(数据对象, 格式说明符)。其用法与str.format()不同但很接近,给初学者增加了可能引起困惑的点。
# 等价写法
# str.format()方法
'{:_}'.format(1234567890)
str.format('{:_}', 1234567890)
# format内置函数
format(1234567890,"_d") '1_234_567_890''1_234_567_890''1_234_567_890'8.4.3 f-字符串
f-字符串是以f为前缀的字符串。 f-字符串的设计目的,是在str.format()的基础上进一步简化代码。
value = 90
# str.format方法
'The value is {}.'.format(value)
# f字符串
f'The value is {value}.''The value is 90.''The value is 90.'f字符串与str.format()的用法基本相同,区别有:
- f字符串可以直接把数据对象变量名称放入
str.format()方法的替换字段部分;而format方法中替换字段只能是索引或关键字参数,还需要将数据对象作为参数传入str.format()。 - f字符串允许替换字段中出现
数据对象名称 =,这样会在输出前添加变量名称与等号。
# 替换字段嵌套
import decimal
width = 10
precision = 4
value = decimal.Decimal("12.34567")
f"result: {value:{width}.{precision}f}" 'result: 12.3457'# 替换字段中含有 数据名称 =
import datetime
today = datetime.datetime(year=2017, month=1, day=27)
f"{today:%B %d, %Y}"
f"{today=:%B %d, %Y}"
f"{today = :%B %d, %Y}" # 可以包含空格
foo = "bar"
f"{ foo = }" 'January 27, 2017''today=January 27, 2017''today = January 27, 2017'" foo = 'bar'"8.5 附:字符串方法速查表
| 方法 | 效果 |
|---|---|
s.isdigit() |
是否全是数字 |
s.isnumeric() |
是否是数字字符(范围比digit更广) |
s.isalpha() |
是否全是字母 |
s.isalnum() |
是否全是数字或字母 |
s.isupper(), s.islower() |
是否全是大写/小写字母 |
s.isspace() |
是否全是空白字符 |
islapha(),isalnum()中所谓的是否是字母(alphabetic),指的是在Unicode字符数据库中被识别为字母的字符,中文等非ASCII字符也在此范围之内。空格不属于字母。
"\n".isspace()True"abc123".isalnum(), "悟空".isalnum(), "悟空 wukong".isalpha()(True, True, False)isdigit()判断是否属于0 \sim 9,上标、全角等数字,isnumeric()在digit的范围之外,还能判断中文数字,罗马数字等。
# 测试各种数字字符
test_cases = ['123', '①', '五','Ⅳ', '1.23', '1,000']
print('字符\tdigit\tnumeric')
print("-" * 20)
for case in test_cases:
print(case, case.isdigit(), case.isnumeric(), sep = "\t")字符 digit numeric
--------------------
123 True True
① True True
五 False True
Ⅳ False True
1.23 False False
1,000 False False| 方法 | 效果 |
|---|---|
s.lower() |
转换为小写 |
s.upper() |
转换为大写 |
| 方法 | 效果 |
|---|---|
s.strip(), s.lstrip(), s.rstrip() |
去除两/左/右端的空格 |
s.center(width[, fillchar])s.ljust(width[, fillchar])s.rjust(width[, fillchar]) |
居中/左对齐/右对齐,用指定字符填充空白 |
| 方法 | 效果 |
|---|---|
s.startswith(prefix) |
是否以字符串prefix开头 |
s.endswith(suffix) |
是否以字符串suffix结尾 |
s.replace(old, new) |
将old替换为new |
s.find(sub) |
返回sub在s中的下标,sub不在s中返回-1 |
s.index(sub) |
返回sub在s中的下标,sub不在s中报错 |
s.count(sub) |
返回sub在s中出现的次数 |
8.6 练习
- 用
input()获取用户名称,打印如下输出。
(总输出长度为30,王小孩为input()获取的用户名称)
============您好,王小孩============- 输出给定半径的圆的面积,保留4位小数,产生如下输出。
(半径2和面积12.5664都是要求格式化的数据,不应当是原样输出的字符串的一部分。)
半径为2的圆的面积为12.5664。- 密码生成器。编程,生成同时满足下列条件的密码:
- 6<=长度<=20
- 包含数字,大小写字母,特殊字符。
# 特殊字符
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~\x61是\xhh类型的字符,\12是\ooo类型的字符,\n是一个换行符,abd是3个字符,因此合计6个字符。↩︎你大概率不会对它们有兴趣的。如果你真的想知道,请看官方文档https://docs.python.org/3/library/stdtypes.html#printf-style-string-formatting↩︎